
What follows is an excerpt from a book I was writing on Causality in 2020. I eventually abandoned the manuscript as the software ecosystem was not mature enough to fold all of causality into 1-2 tools. Recently I took out the manuscript again, to share some basic insights with a colleague, and I realised that it would also make sense to share an extract here.
Continue reading “The Counterfactual Revolution”Autumn Reading List
I developed a Reading List in Autumn 2021 to educate people about AI in Healthcare. As an aid to navigating a selection of my blog posts, here is the complete reading list:
- Translation in medical AI.
- Building a medical AI product (product development framework).
- Bioinformatics business models.
- Predictive Models.
- Regulating AI in Medical Products (OnRAMP).
- Leadership / managing people.
- Data science in biomedical industry.
- Pharma’s data problem.
- Knowledge worker operating manual.
- Personalised medicine, what is it?
- RCT vs RWE.
- AI in Healthcare 101.
- 5 big challenges facing medical AI.
- Differentiation.
- Math and Bio 2.0.
This list is thematically coherent and should give you a good starting point for exploring this blog.
December 2023 update
I stopped posting updates to this blog almost one year ago. At the time, I was deeply involved in producing yet another academic paper (It’s out!) and we had just had our second child.
I still like the process of writing my ideas and sharing them with others. But the process has become too time consuming. And, sadly, the payoff in a noisy world is pretty thin.
Having some experience of the whole key-opinion-leader (KOL) process I don’t think that I’m ever going to be very successful on that path.
Decisions
Three key decisions are relevant for the current post
- Commission somebody to redesign this site. I need to make it more navigable, so that you the reader can access the more relevant posts on your first visit.
- Post considerably less frequently. Yes I will begin to write again, but the articles will only be posted after the redesign.
- Display a thread of some of my most relevant articles as a first contact point for the interim. (Coming next week).
About me
I am still a life-sciences and technology founder. I still prefer the technical rather than business role, although I frequently do both albeit rarely at the same time. I came very close to founding a Software-as-a-InVitro-Diagnostic (SaIVD) company in 2023, unfortunately our hopes did not come to fruition. I earn my income from advising others on Team, Architecture and Build. Mostly I get paid to solve serious problems. I also do due diligence for investors.
Why the innovation snippets?
For six months now, I have been producing an innovation snippets series.
I know I have some email subscribers who have been surprised at my output in the past six month (Hi Ronan!). Partly, it was surprising that I chose to publish on this topic given my time commitments elsewhere, and partly it was surprising as I tend to have a much stronger interest in heavy technical questions and a focus on product-market fit in healthcare.
I have spent the past five plus years deeply involved in medical innovation. My first startup was in pharma R&D, and my second was an innovative approach to delivering behavioural therapy to oncology patients. Since leaving Fosanis, I have spent over three years publishing academic articles on how to do medical AI products, and in mentoring a rather large number of startups working in this space.
I realise that I do not want to become a lifelong coach. Nor am I likely to publish a book on entrepreneurship. But I have been systematically gathering my insights over these past years and if the opportunity ever presents I do intend to publish them – that is just not my principal path.
In June 2022 I accepted a full time job for the first time in my career. Part of that role might have required me to develop content for courses on innovation in AI. Prior to beginning in that role I was faced with the obvious problem – I have a lot of content ready to go, I was not hired on the basis of having that content, indeed my employer did not even know that I had it at the point where they hired me, so how do I maintain ownership here?
We came up with an internal process for handling this issue. But my backstop solution was to publish the insights in their rawest form here on my blog. I typed them all up prior to taking up my employment and programmed their subsequent appearance according to a weekly publishing schedule.
What next?
I like the insights, but I dislike what they are doing to my blog.
I use this domain as my principal domain for my professional life and this is lowering my value. It is hiding that I am actually a technical expert who, in addition, works well with humans.
I will revert to publishing on more concrete topics. But I am bandwidth limited so, as a consequence, I will be forced to publish less often.
If it does not make the blog look bad then I will continue to intersperse innovation insights when time and space allow.
Valuing an early-stage startup
I had an interview recently in which I was asked how I value an early-stage startup. The following mind-map was my answer.
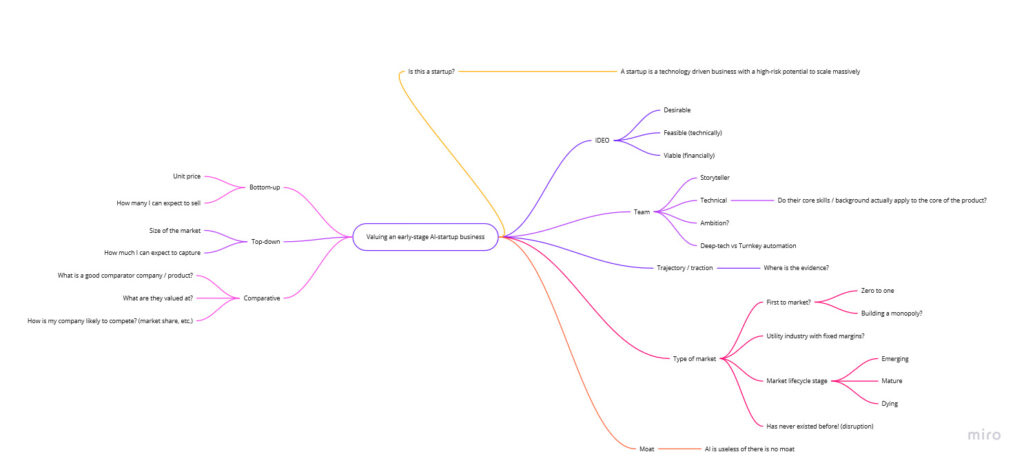
The first question is, is this a startup? People in government funding agencies like to dispute definitions so I want to be clear, I’m only talking about companies – typically involving a technological approach – with a high-risk potential for enormous growth.
Then I take the IDEO three lenses approach to product innovation. Is the solution desirable, feasible and viable. And what is the evidence for each?
How to the team look? When I began founding, team was the only thing I was interested in. Working with German investors pushed me off that topic for a while – they don’t care about team, they want a turnkey solution for profitability (i.e. they are not VCs). But I subsequently returned to my roots. With a poor team you might build a business, but you will not build a high-return entity. You need the best.
Are the team ambitious? Is there a good storyteller amongst them? To what degree is this a deep-tech vs direct execution startup? And on the technical side, does the background of the technical partner(s) line up with the product needs? An MIT degree is great, but not if it’s in the wrong topic.
Trajectory and traction are of course the best indicators. However, these are hard to measure at an early-stage, and talented founders control the information flow to appear to have generated sudden traction, when actually it’s the work of years and mommy and daddy’s best efforts.
What kind of market is the startup in? Peter Thiel has described the zero to one phenomenon. Will they be first to market? Is this a likely monopoly marketplace? Let’s not forget that it’s usually third to market who, improving upon the mistakes of others, holds the terrain. Where are we in the market lifecycle? Early – mature – late? Is this product a potential disruption? In the latter case then a lot of metrics are upended.
Finally, a company needs a moat. Unless you are a me-too product, entering an already crowded marketplace – in which case venture funding is inappropriate – you should have some form of theoretical moat.
On the left-hand side of the map I summarise the three primary methodologies for actually pricing the startup / market. Bottom-up numbers are built upon unit prices and sales forecasts. Top-down are based upon how much of the market you can capture. And comparative numbers are derived from analogy to companies with similar products or similar strategies, often in a different field.
[This article is part of the Innovation Snippets series]
Two career approaches
Identify what you need to do to get the role, and only do that. This is effective in a low volatility, fixed returns situation, e.g. becoming a doctor.
Build a portfolio of skills and identify a market for them. This is the effectuation approach. It doesn’t require planning, is considerably more volatile, but does not cap the potential rewards (tangible and intangible).
[This article is part of the Innovation Snippets series]
Getting free studies
Consider donating a prototype to an adjacent academic discipline and allowing them to generate hype for you by applying your product to their field.
What do I mean by this?
Forget the studies for your own field of application. You will need to do those yourself.
There are disciplines (e.g. psychophysics) which are crying out for new toys to play with. If your device fits the bill then give them one and ask them to try it out.
Academic papers are a form of currency.
[This article is a part of the Innovation Snippets series]
Medical evidence requirements are purpose specific
The required level of evidence in regulatory affairs is essentially pass-fail.
Reimbursement questions are graded. Moreover, there are hidden failing grades – where you get reimbursed but your evidence was so weak you cannot sustain a business.
[This article is part of the Innovation Snippets series]
Re-examining talkers vs doers
There has been a lot of discussion about talkers vs doers in the startup ecosystem. Talkers are the sales people, the CEOs if you like. Doers are often the tech people.
The talkers tend to have an ‘ask the community’ approach to everything.
Perhaps the talkers have over-indexed on always asking for help. They are in a power-law system and there can be only one top-dog. For simple systems always asking for help can work. But this does not scale.
Moreover doers cannot put up with this level of noise and still build the products.
[This article is part of the Innovation Snippets series]
Elon Musk 2.0
A different take on how Elon Musk evaluates opportunities:
- How long will it take to build?
- Do I have access to the right resources?
- Can I obtain the required raw materials?
[This article is part of the Innovation Snippets series]